Quelques limites des LLMs en production n8n
Item
- Title
- Quelques limites des LLMs en production n8n
- Description
- Les résumés chronologiques initiaux se sont révélés trop génériques pour un usage opérationnel, tandis que l’extraction de citations par le LLM se biaisait vers le début de la conférence en l’absence de contrainte de distribution temporelle. Des prompts devenus trop volumineux ont accru les risques de troncature et de perte de contexte sur de longs SRT, aggravés par les plafonds de tokens des nœuds dans n8n. De plus, peu de modèles utilisent de façon stable la fonction d'appel d'outil dans n8n, compliquant l’appel au RAG lors de l’association de mots‑clés, ce qui impose d’optimiser la charge contextuelle selon la taille du SRT. L'ajustement des division en segments avec léger recouvrement, des prompts précis et détaillé adapté à chaque tâche on été tentés . Résultats, une meilleure couverture des contenus et le fil argumentatif est mieux respecté, les micro résumés sont plus précis et les mots‑clés sont plus discriminants après les itérations de prompts et une segmentation adaptée. Dans le cas du RAG, la tokenisation peut fragmenter les formes avec traits d’unions, conduisant à des termes tronqués. Par exemple, “Post‑vérité” sera réduit à “vérité”. Ce qui peu être mitiger par une normalisation, l'ajout de formes composées dans la base vectoriel ou encore par un simple nœud de code Javascript en post‑traitement.
- Photo / Vidéo de cette expérimentation
-
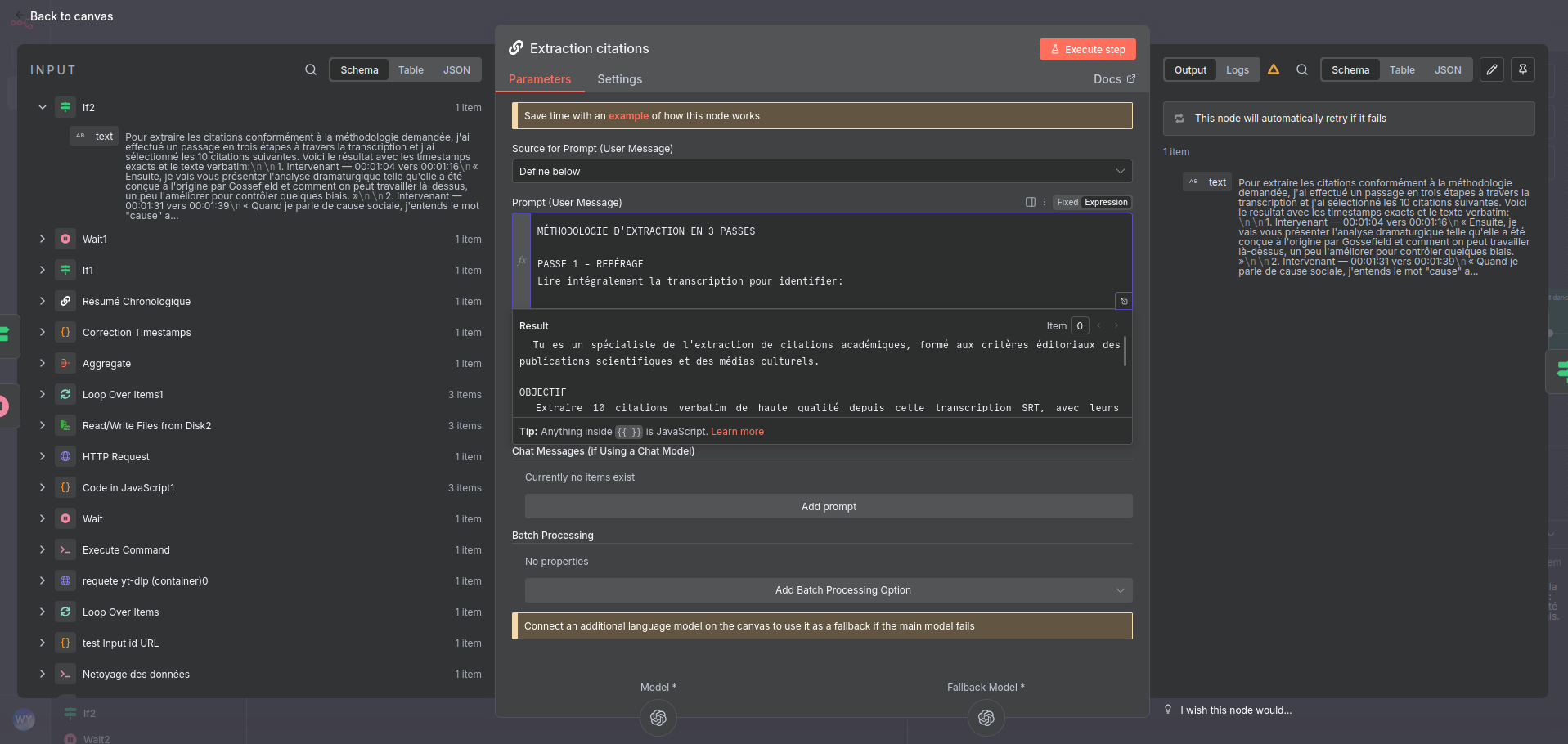
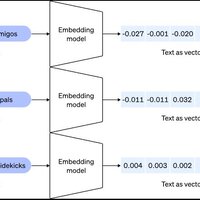
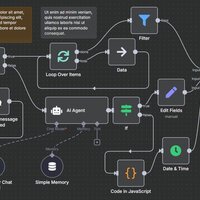
 Capture d'écran du workflow n8n 2
Capture d'écran du workflow n8n 2
- Succès / Avancées notables
- Passage d’un résumé chronologique monolithique à des micro résumés segmentés, d’abord à 5 minutes puis en longueur adaptative pour mieux capturé l'intégralité du propos.
- Forte amélioration de la couverture temporelle après le renforcement des prompts et la segmentation.
- Stratégie de filtrage des résultats pour augmenté la qualité finale.
- Problèmes rencontrés
- Résumés chronologiques initiaux trop génériques et inapte à une application concrète.
- LLM « paresseux » en extraction de citations, biaisé vers le début de la conférence si aucune contrainte de distribution temporelle n’est imposée.
- Prompts devenus très volumineux pour le résumé thématique, avec risques de troncatures et perte de contexte sur de longs SRT.
- Peu de modèles peuvent utilisé de manière stable les outils dans n8n, ce qui pose problème dans notre cas lors de la sollicitation du RAG lors de l'association des mots-clés.
- Limites de tokens du côté des nœuds n8n et nécessité d’optimiser la charge contextuelle selon la taille du SRT.
- Solutions apportées
- Prompts contraignant la couverture par tranches temporelles puis adoption de micro résumés à longueur adaptative pour s’ajuster au contenu varié du langage orale.
- Suggestions pour d’autres expérimentateur.ices
- Priorisé l'utilisation de noeud de code pour les tach précise et utilisé les LLMs uniquement pour leur flexibilité et non pour leur rigoureur
- Actant ayant créé ce retour d'expérience
-
 Keven Laporte
Keven Laporte
- Modifications envisagées
- Ajouter un agent IA comme superviseur pour assuré la qualité de chaque génération en relançant la génération en cas de résultat insatisfaisant.


- Item sets
- EdiSem (Travaux étudiants)
Linked resources
| Title | Class |
|---|---|
 Automatisation du traitement de résumés de conférences académiques par un workflow n8n Automatisation du traitement de résumés de conférences académiques par un workflow n8n |
Annotations
There are no annotations for this resource.