-
 Effet d'Entrainement / LABORARE collectif
Effet d'Entrainement / LABORARE collectif
-
 Becky Chambers
Becky Chambers
-
 Antonio Strati
Antonio Strati
-
 Jane Bennett
Jane Bennett
-
 Michel Callon
Michel Callon
-
 The Long Way to a Small, Angry Planet (Wayfarers, vol. 1)
The Long Way to a Small, Angry Planet (Wayfarers, vol. 1)
-
 Organization and Aesthetics
Organization and Aesthetics
-
 Vibrant Matter: A Political Ecology of Things
Vibrant Matter: A Political Ecology of Things
-
 Éléments pour une sociologie de la traduction : La domestication des coquilles Saint-Jacques et des marins-pêcheurs dans la baie de Saint-Brieuc
Éléments pour une sociologie de la traduction : La domestication des coquilles Saint-Jacques et des marins-pêcheurs dans la baie de Saint-Brieuc
-
 Que diraient les animaux, si… on leur posait les bonnes questions ?
Que diraient les animaux, si… on leur posait les bonnes questions ?
-
 L'individuation psychique et collective
L'individuation psychique et collective
-
 Par-delà nature et culture
Par-delà nature et culture
-
 Marine Theunissen
Marine Theunissen
-
 Les IA en partenaires : créer de nouveaux narratifs sur nos relations avec la technologie via la scène
Les IA en partenaires : créer de nouveaux narratifs sur nos relations avec la technologie via la scène
-
 Rémy Sohier
Rémy Sohier
-
IA générative et pipelines en recomposition : enjeux pédagogiques en situation de production
-
 GPT-5 mini
GPT-5 mini GPT-5 mini est un modèle de langage génératif multimodal développé par OpenAI, version compacte et optimisée de GPT-5. Il est conçu pour des environnements à haute volumétrie, faible latence et sensibles aux coûts, tout en conservant de solides capacités généralistes. Il supporte le texte et les images en entrée, génère du texte en sortie, et dispose de capacités de raisonnement avancé, d'appel de fonctions, de recherche web intégrée, et de sorties structurées (JSON). Le modèle offre une fenêtre de contexte de 272 000 tokens avec jusqu'à 128 000 tokens en sortie, et intègre un paramètre reasoning_effort ajustable (minimal, low, medium, high) permettant aux développeurs de calibrer le compromis entre vitesse et profondeur de raisonnement.
-
 Posthumains
Posthumains
-
 i/O
i/O
-
 Post Humains
Post Humains
-
Mark Wachholz
-
 Neil Smith
Neil Smith
-
 Ilya Sutskever
Ilya Sutskever
-
 Alex Krizhevsky
Alex Krizhevsky
-
 Fuck les whites
Fuck les whites
-
 Renversement
Renversement
-
 Souffler les braises
Souffler les braises
-
 The cinema that never was
The cinema that never was
-
 Bang Crunch
Bang Crunch
-
 Imagenet classification with deep convolutional neural networks
Imagenet classification with deep convolutional neural networks
-
Les barrières à l'emploi de l'IA générative dans le cinéma indépendant
-
Mettre en scène l’IA : récits, idéologies et pratiques artistiques
-
 John von Neumann
John von Neumann
-
 The computer and the brain
The computer and the brain
-
 Doron Swade
Doron Swade
-
Xavier Guchet
-
Matthieu Tixier
-
Michel J. F. Dubois
-
Michel J. F. Dubois
-
Nathalis Kroichvili
-
Nicolas Simoncini
-
Bénédicte Rey
-
Charles Lenay
-
Pierre Steiner
-
Laurent Heyberger
-
Guillaume Carnino
-
José Halloy
-
Michel Dubois
-
Victor Petit
-
 Mathieu Triclot
Mathieu Triclot Enseignant-chercheur en philosophie, spécialiste de la philosophie des techniques; ses travaux portent sur l’information, les jeux vidéo et plus récemment sur les projets de conception technologique et la notion de milieu technique.
-
 Prendre soin des milieux : manuel de conception technologique
Prendre soin des milieux : manuel de conception technologique
-
 Ingénierie des connaissances et des contenus : le numérique entre ontologies et documents
Ingénierie des connaissances et des contenus : le numérique entre ontologies et documents
-
 Le sens de la technique : le numérique et le calcul
Le sens de la technique : le numérique et le calcul
-
 David Louapre
David Louapre Chercheur en physique et en intelligence artificielle, vulgarisateur scientifique et créateur de la chaîne YouTube Science Étonnante.
-
 Bruno Bachimont
Bruno Bachimont
-
La créativité et la distribution de probabilités
-
Énonciation et modélisation dans l'IA générative, l'approche 3D (dire, dit, désigné)
-
 CAN: Creative Adversarial Networks, Generating “Art” by Learning About Styles and Deviating from Style Norms
CAN: Creative Adversarial Networks, Generating “Art” by Learning About Styles and Deviating from Style Norms
-
Marian Mazzone
-
Mohamed Elhoseiny
-
Bingchen Liu
-
Ahmed Elgammal
-
 Attention Is All You Need
Attention Is All You Need
-
Illia Polosukhin
-
Łukasz Kaiser
-
Aidan N. Gomez
-
Llion Jones
-
Jakob Uszkoreit
-
Niki Parmar
-
Noam Shazeer
-
Ashish Vaswani
-
 Yann LeCun's new venture is a contrarian bet against large language models
Yann LeCun's new venture is a contrarian bet against large language models
-
 A Path Towards Autonomous Machine Intelligence
A Path Towards Autonomous Machine Intelligence
-
Life Being: Living Quantum Art
-
Théo Gautier
-
Luc Pinguet
-
Laurine Capdeville
-
Eloïse Tassin
-
Félix Olart
-
 Quantum Nodes: Quantum Computing Applied to 3D Modeling
Quantum Nodes: Quantum Computing Applied to 3D Modeling
-
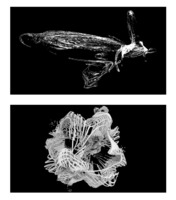 Quantum Beings
Quantum Beings
-
 Quantum Computing for Art Exploration and Creation
Quantum Computing for Art Exploration and Creation
-
 Being paintings
Being paintings Texte présentant le projet « Being paintings » dans le contexte de la galerie d’art de SIGGRAPH 2005, où des créatures virtuelles, issues d’algorithmes évolutifs et de réseaux neuronaux, génèrent des œuvres picturales dynamiques.
-
IA et créativité dans les arts numériques
-
 Alain Lioret
Alain Lioret
-
L'intelligence artificielle comme milieu narratif et esthétique
-
 Andrew Ayers Stanton
Andrew Ayers Stanton Réalisateur, scénariste, producteur, animateur et doubleur américain né le 3 décembre 1965 à Boston (Massachusetts). Diplômé d'un BFA en Animation de Personnages à l'Institut Californien des Arts (CalArts).
-
 The Clues to a Great Story
The Clues to a Great Story
-
 Marcia J. Bates
Marcia J. Bates rofesseure émérite de Science de l'Information à l'UCLA (University of California, Los Angeles), Marcia J. Bates est une figure majeure de la discipline. Elle a obtenu son Ph.D. en Science de l'Information à l'Université de Californie à Berkeley en 1969 et a rejoint l'UCLA en 1972.
-
 Fundamental Forms of Information
Fundamental Forms of Information DOI : 10.1002/asi.20369. Article fondateur en science de l'information, définissant l'information comme « schéma d'organisation de la matière et de l'énergie » et introduisant la distinction entre information naturelle (physique), représentée (symbolique), encodée et incarnée.
-
 John Truby
John Truby Scénariste, réalisateur, consultant en écriture (script doctor) et pédagogue américain né en 1952. Surnommé « le meilleur script doctor de l'industrie cinématographique », il a été consultant sur plus de 1 800 films, séries télévisées et sitcoms pour Disney, Universal, Sony Pictures, Fox, HBO, Paramount et la BBC.
-
 L'Anatomie du scénario : comment devenir un scénariste hors-pair
L'Anatomie du scénario : comment devenir un scénariste hors-pair
-
 Robert McKee
Robert McKee Titulaire d'un Bachelor en Littérature Anglaise et d'un Master en Arts de la Scène à l'Université du Michigan, il débute sa carrière comme acteur et metteur en scène de théâtre, puis devient scénariste à Hollywood à la fin des années 1970. En 1983, boursier Fulbright, il rejoint la Faculté de Cinéma et de Télévision de l'Université de Californie du Sud (USC) où il développe son célèbre séminaire STORY; un cours intensif de 30 heures sur 3 jours, donné depuis en salles combles à travers le monde.
-
 Story : Contenu, structure, genre — Les principes de l'écriture d'un scénario
Story : Contenu, structure, genre — Les principes de l'écriture d'un scénario
-
 Pierre Dukan
Pierre Dukan Pierre Dukan est diplômé de médecine à l'Université de Toulouse et s'est spécialisé en nutrition à l'hôpital Saint-Louis de Paris en 1970. Fondateur du régime Dukan, une méthode hyperprotéinée en 4 phases. Radié du tableau de l'Ordre des médecins en 2014 pour promotion commerciale de sa méthode, il demeure une figure controversée de la nutrition grand public et a connu un retour médiatique notable sur TikTok en 2024.
-
 Le livre de mon poids
Le livre de mon poids
-
 Vladimir Yakovlevich Propp
Vladimir Yakovlevich Propp Folkloriste et philologue soviétique d'origine allemande (nom de naissance : Hermann Waldemar Propp). Fils de paysans germano-Volga russifiés, il étudie la philologie russe et germanique à l'Université de Saint-Pétersbourg (1913–1918). En 1932, il rejoint la faculté de l'Université d'État de Leningrad, où il dirige la Chaire de Folklore à partir de 1938 jusqu'à son intégration au Département de Littérature russe, y enseignant jusqu'en 1969. Fondateur de la méthode comparative et typologique en folkloristique et l'un des pères fondateurs de la théorie contemporaine du texte
-
 Morphologie du conte
Morphologie du conte
-
 Université de Toulouse
Université de Toulouse
-
 Peter Stockwell
Peter Stockwell Linguiste et stylisticien britannique, il détient la Chaire de Linguistique Littéraire à l'Université de Nottingham (Royaume-Uni), où il a obtenu son BA en langue et littérature anglaises à l'Université de Liverpool (1988) puis son Ph.D. (1991). Fondateur du domaine de la poétique cognitive anglophone, il est Fellow de la English Association (FEA) depuis 2012. Il a également occupé les fonctions de Vice-Doyen et de Pro-Vice-Chancelier associé pour l'engagement mondial.