Entrainement de LoRA (Low Rank Adaptation model) avec diffusion_pipe pour la génération vidéo
Item


- Title
- Entrainement de LoRA (Low Rank Adaptation model) avec diffusion_pipe pour la génération vidéo
- Description
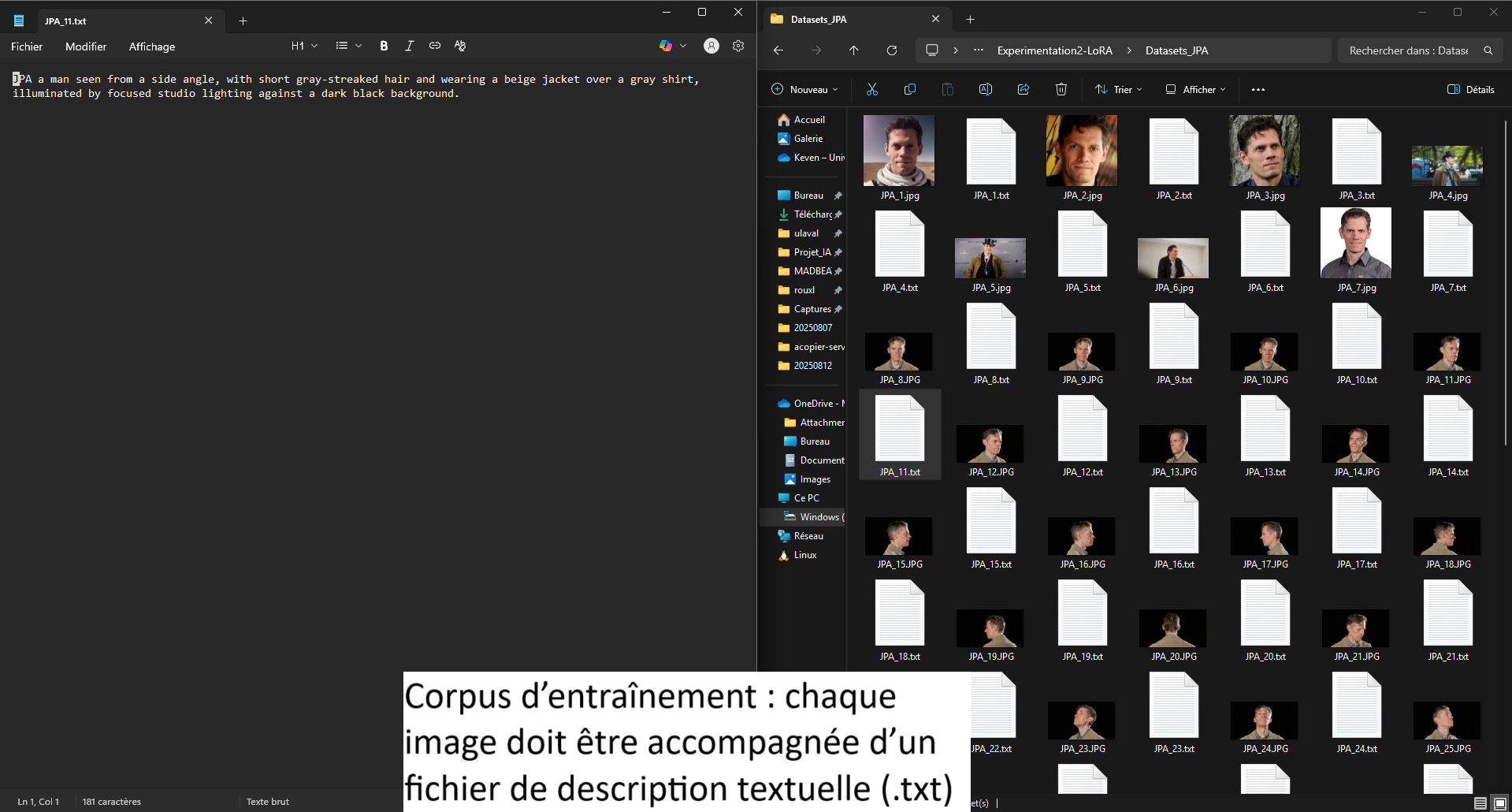
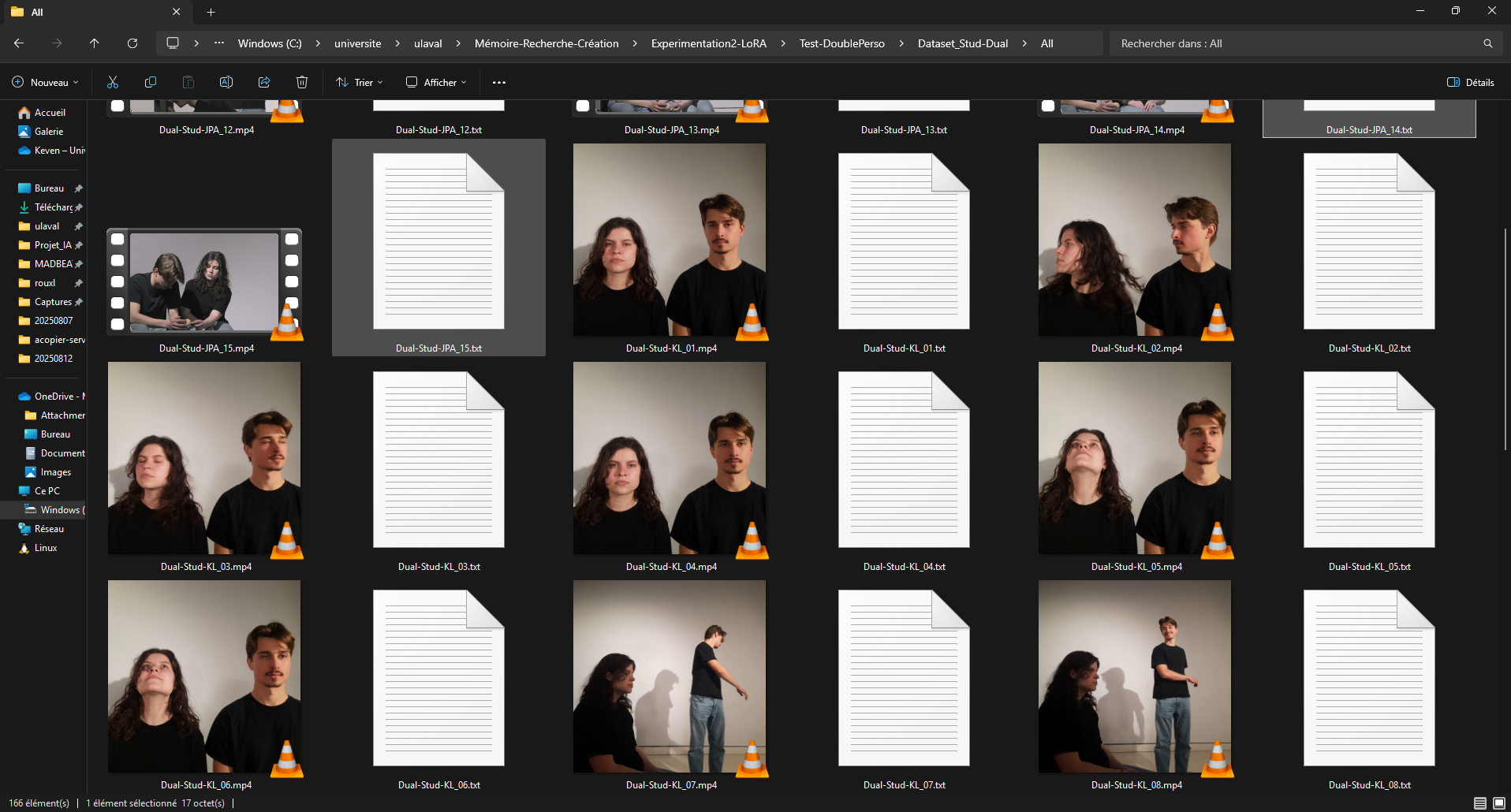
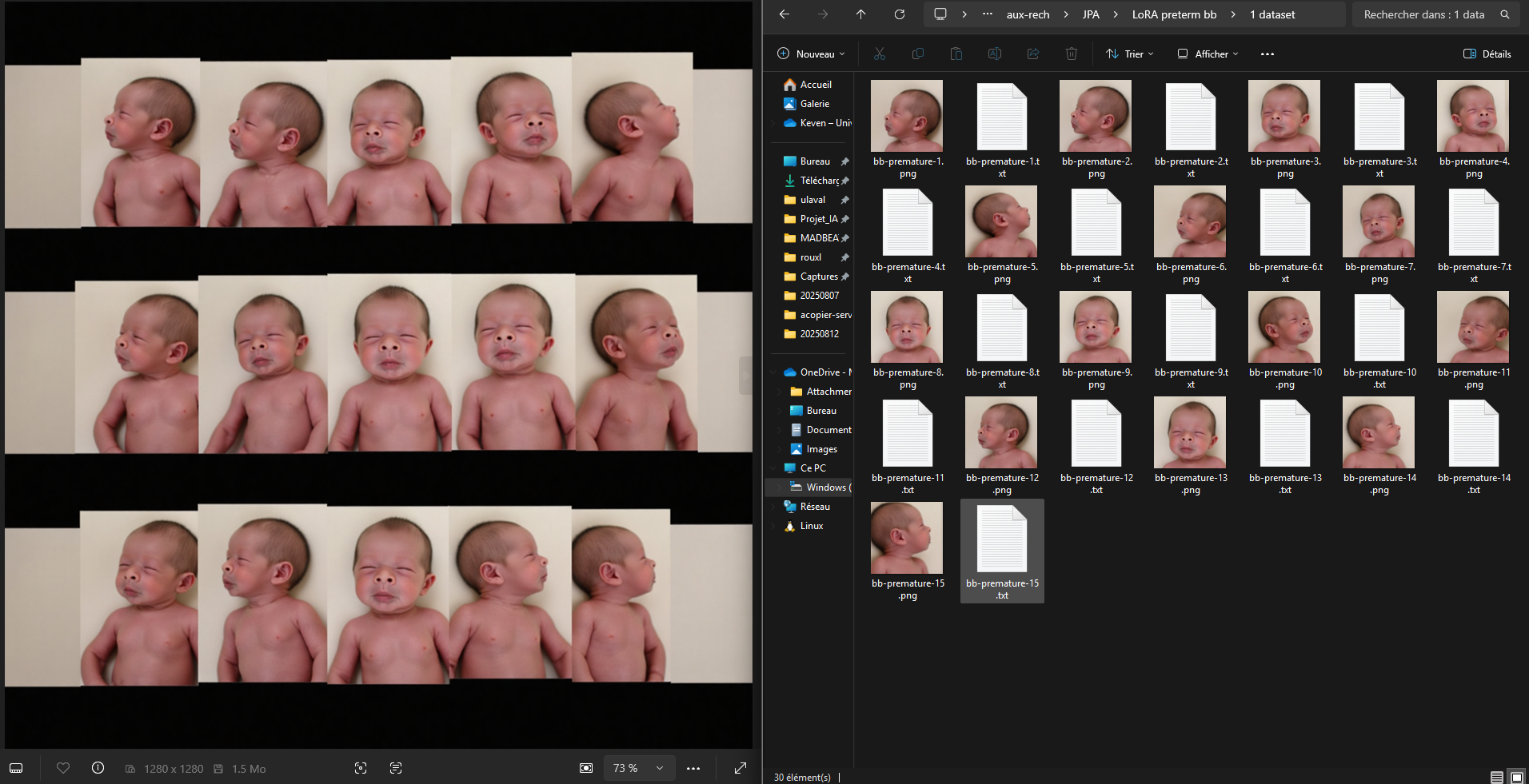
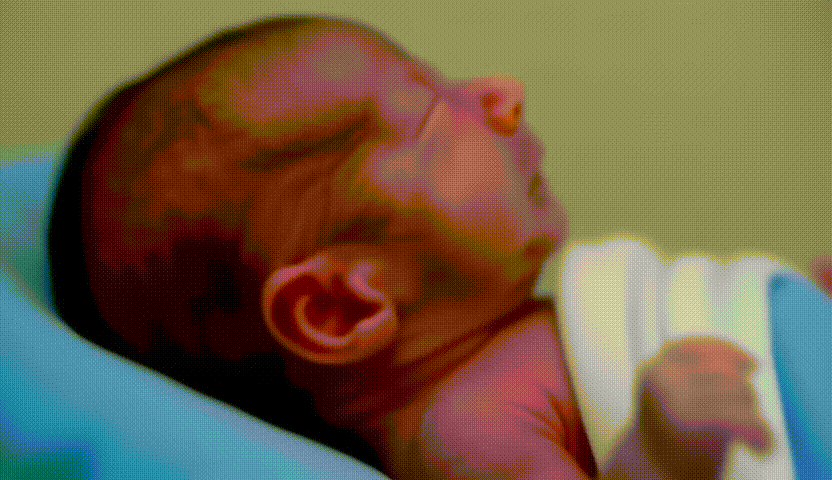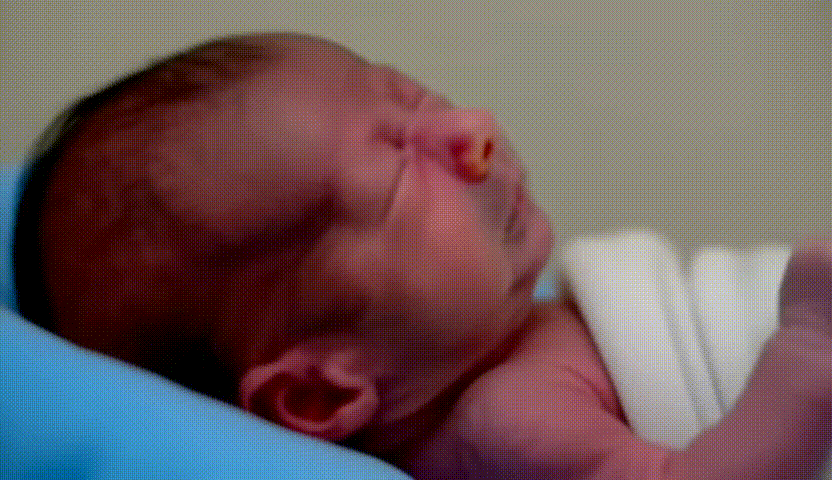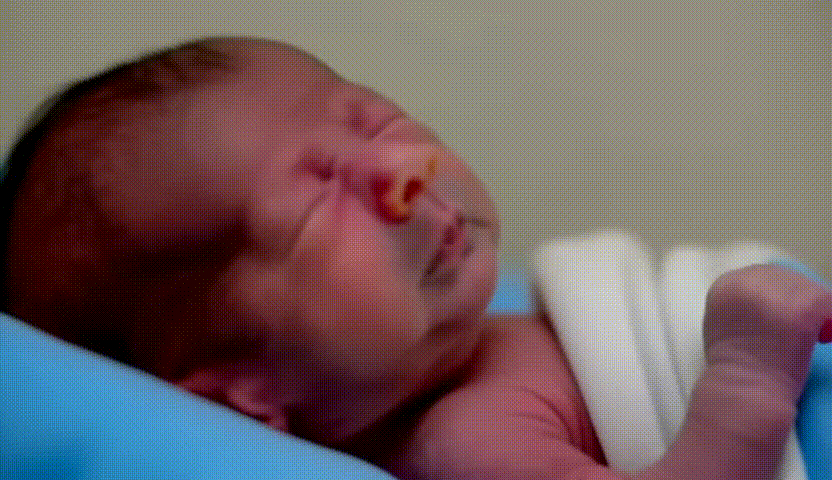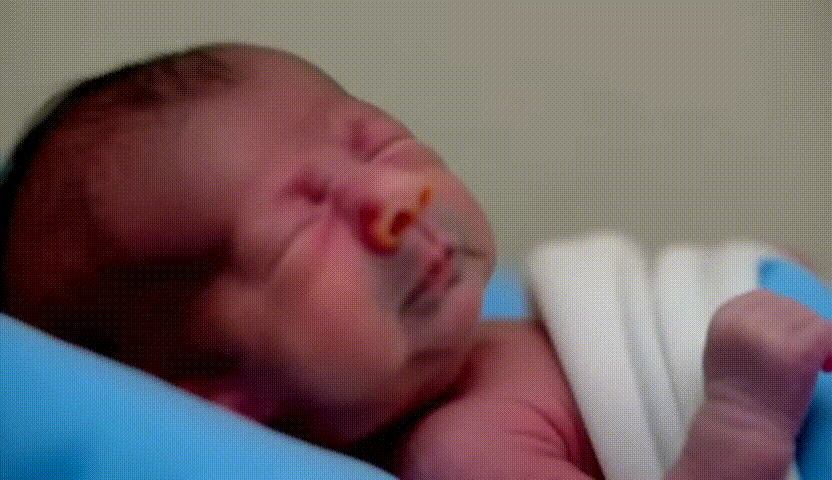
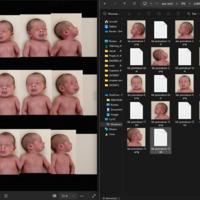
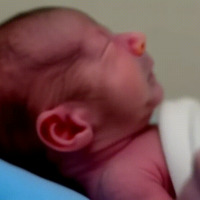
- Retour d’expérience ciblé sur l’entraînement de modèles LoRA avec diffusion_pipe et diffusion_pipe_ui dans le cadre du projet Isolette. Trois séries de tests ont été menées : la première sur des portraits de Keven Laporte et Jeremy Peter Allen ; la deuxième sur des étudiant·es au BAC ; la troisième sur des images générées à partir du model Flux [Dev] d'un bébé prématuré. Cette méthode s’avère particulièrement puissante pour la création de deepfakes ultra-réalistes, ou pour maintenir une cohérence de personnages, de lieux et de styles à travers plusieurs générations de vidéos. L’expérimentation met en avant le potentiel du pipeline diffusion_pipe/LoRA pour produire des avatars et des scènes sur mesure, aussi bien pour la recherche-création que pour des applications artistiques avancées.
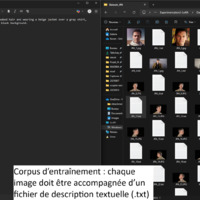
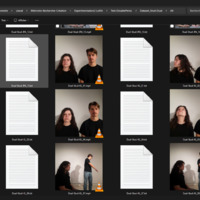
- Photo / Vidéo de cette expérimentation
-
 image pour Entrainement de LoRA (Low Rank Adaptation model) avec diffusion_pipe 6
image pour Entrainement de LoRA (Low Rank Adaptation model) avec diffusion_pipe 6
-
 image pour Entrainement de LoRA (Low Rank Adaptation model) avec diffusion_pipe 5
image pour Entrainement de LoRA (Low Rank Adaptation model) avec diffusion_pipe 5
-
 image pour Entrainement de LoRA (Low Rank Adaptation model) avec diffusion_pipe 4
image pour Entrainement de LoRA (Low Rank Adaptation model) avec diffusion_pipe 4
-
 image pour Entrainement de LoRA (Low Rank Adaptation model) avec diffusion_pipe 3
image pour Entrainement de LoRA (Low Rank Adaptation model) avec diffusion_pipe 3
-
 image pour Entrainement de LoRA (Low Rank Adaptation model) avec diffusion_pipe 2
image pour Entrainement de LoRA (Low Rank Adaptation model) avec diffusion_pipe 2
-
 image pour Entrainement de LoRA (Low Rank Adaptation model) avec diffusion_pipe 1
image pour Entrainement de LoRA (Low Rank Adaptation model) avec diffusion_pipe 1
- Insérer un template outils
-
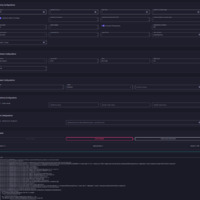 diffusion_pipe_new_ui
diffusion_pipe_new_ui
- Succès / Avancées notables
- L'entrainement de LoRA avec diffusion_pipe_ui fonctionne.
- Problèmes rencontrés
- Incapacité d'entrainé un LoRA pour Wan2.1 sur diffusion_pipe
- L'effet du LoRA n'est pas satisfaisant (non-ressemblance des visages ou visages statiques)
- Difficultés récurrentes pour entraîner des LoRA avec diffusionpipeui : erreurs d’import de fichiers .jpg pourtant supportés.
- Pour permettre la consistance des personnages lors des plans contenant deux personnages, nous avons testé d'utilisé conjointement deux LoRA, un pour chaque personnage, dans notre workflow ComfyUI. Cependant, le modèle tentant de superposé les deux LoRA sur les même personnage
- Solutions apportées
- Réduction de résolution des images pour garantir compatibilité. Malgré la capacité de diffusion_pipe à redimensionné les image du dataset avant l'entrainement, certaine résolution semblait faire cracher le logiciel. En ajustant la dimension des image en 512 x 512 (le format utilisé lors de cette entrianement) cela garantissait la compatibilité des images du dataset.
- Suggestions pour d’autres expérimentateur.ices
- Bien qu'il possible d'entrainé un LoRA de génération de vidéo à partir uniquement d'image, je recommande d'ajouté de courtes videos (2 à 3 seconde) du visage en mouvement et lors de dialogue. Ainsi cela garenti de fourni les donné nécéssaire au model pour généré tout les frames nécéssaire pour recréer le mouvement. On peux voir cela un peu comme en animation, les images fournissent les images-clés contenant les détails et les videos fournissent les image filées afin de donné les information nécéssaire pour l'impression de fluidité du video. Concrètement, cela permettra davoir des mouvement plus fluide et réaliste du visage.
- Plus le dataset est volumineux et varié plus le résultat sera performant et flexible. Si vous observé un défaut lors de tel type de génération de vidéo, ajouté ce type de média dans le dataset pour corrigé le trait.
- Attendre que diffusion_pipe sois compatible avec les nouveaux modèle et mettre le logiciel à jour.
- Actant ayant créé ce retour d'expérience
-
 Keven Laporte
Keven Laporte
- Prolongements possibles
- Pour un entrainement optimal, il est recommande d'avoir plusieurs résolution différente des images contenue dans le dataset et de configurer l'entrainement afin que la résolution des images augmente au fur du processus.
- Item sets
- EdiSem (Travaux étudiants)


Linked resources
| Title | Class |
|---|---|
 Isolette Isolette |
Annotations
There are no annotations for this resource.