Chaoticum Seminario : stimulations aléatoires de discussions scientifiques
Item
-
Titre de la conférence
-
Chaoticum Seminario : stimulations aléatoires de discussions scientifiques
-
Date de la conférence
-
21 October 2022
-
Résumé
-
Les scientifiques sont depuis longtemps outillées afin d’optimiser les observations servant de base aux faits analysés, par exemple avec le microscope, l’accélérateur de particules, les formulaires d’enquêtes en ligne ou la constitution automatique de corpus à partir des archives numérisées. Les outils qu’ils utilisent servent aussi à formaliser leurs discours pour faciliter leurs éditorialisations et leurs diffusions, par exemple avec un traitement de texte, des bases de données ou des plateformes Web. Le plus souvent, ces outils servent à satisfaire l’injonction mondiale de produire toujours plus afin de monter dans la hiérarchie des classements scientifiques et des institutions de légitimation. Les productions scientifiques sont désormais soumises aux règles de la « Grande distribution » qui transforment le chercheur en prolétaire alimentant une méga-machine productrice de connaissances. Le prototype que nous présentons dans ce séminaire propose un autre modèle de production scientifique qui privilégie la stimulation des discussions entre humains à partir d’un processus aléatoire d’exploration des connaissances.
-
résumé thématique généré par IA
-
Samuel Szoniecky présente une expérimentation sur les nouvelles formes d'écriture et de discours scientifique, utilisant un générateur de conférences alimenté par des sources diverses. L'expérience est décrite comme une exploration de l'abondance des données disponibles et des nouveaux modes de communication scientifique. Malgré quelques difficultés techniques et déviations humoristiques, Samuel Szoniecky cherche à stimuler la réflexion sur la manière dont ces outils peuvent être utilisés dans la recherche et l'enseignement. Il présente un projet où sont utilisées différentes sources telles que des conférences, des notes de Zotero, des vidéos de séminaires, des programmes de recherche, et des bases de données pour créer un système automatisé d'extraction de citations et de fragments de textes. L'objectif est de fournir un résumé succinct des séminaires Arcanes, en évitant l'exhaustivité et en favorisant une approche fragmentaire pour stimuler de nouvelles idées.
-
Citation tirée de la conférence
-
« Les données disponibles pour faire de la recherche, pour construire un discours scientifique sont de plus en plus nombreuses. Il y a une matière énorme de disponible, sans parler de la matière que chaque chercheur produit au cours de sa carrière et qui a tendance à être de plus en plus importante, ne serait-ce que pour répondre aux impératifs d'évaluation ou de classement des scientifiques. Donc on est vraiment dans une prolifération de l'information, des données, des datas, et il me semble qu'on est peut-être à un tournant aujourd'hui, qui s'amorce déjà depuis quand même un petit peu de temps, sur de nouveaux modes d'écriture, de nouveaux modes de constitution du discours scientifique. »
-
« L'idée à travers tout ce dispositif c'est vraiment de dire : "ok, on n'a pas le temps de pouvoir voir l'intégralité des cinquante heures de séminaires Arcanes, comme on n'a pas le temps de voir l'exhaustivité de ce que nous a présenté Arnaud [Laborderie]". Et donc on peut effectivement utiliser les machines pour faire des traitements statistiques, ce que nous a un peu montré Arnaud autour de constitution de corpus et d'analyse automatique des corpus pour essayer d'en extraire une sorte de résumé évitant de tout se coltiner, ou une autre méthode expérimentale, celle que je viens de tenter devant vous, qui est de dire : "au lieu de partir de l'exhaustivité, prenons plutôt l'aspect fragmentaire des choses, et à travers les fragments, regardons si on ne peut pas avoir des stimulations qui permettraient ensuite peut-être d'approfondir, de découvrir des sources qu'on ne connaît pas, ou même de générer des idées auxquelles on n'aurait pas pensé." »
-
Type de la conférence
-
séminaire
Annotations
There are no annotations for this resource.
 Samuel Szoniecky
Samuel Szoniecky
 Figures de l'imminence. Pour une lecture philosophique du Yi King.
Figures de l'imminence. Pour une lecture philosophique du Yi King.
 Readings in Information Visualization. Using Vision to Think
Readings in Information Visualization. Using Vision to Think
 Éditions critiques : nouveaux outils, nouvelles possibilités
Éditions critiques : nouveaux outils, nouvelles possibilités
 L'avare
L'avare
 Caractérisation des bonnes pratiques en éco-conception pour la formation des ingénieurs-concepteurs : Synthèse des dimensions, méthodes, activités et outils
Caractérisation des bonnes pratiques en éco-conception pour la formation des ingénieurs-concepteurs : Synthèse des dimensions, méthodes, activités et outils
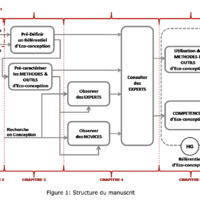 Structure du manuscrit
Structure du manuscrit